无锁化设计
lock-free vs spin-lock¶
-
lock-free和spin-lock核心技术都是采用CAS。 -
lock-free示例代码:#include <stdio.h> #include <stdatomic.h> #include <pthread.h> static void * adding(void *input); int count = 0; int main() { pthread_t tid[10]; for(int i = 0; i < 10; i++) { pthread_create(&tid[i], NULL, adding, NULL); } for(int i = 0; i < 10; i++) { pthread_join(tid[i], NULL); } printf("the value of count is %d\n", count); } static void * adding(void *input) { int val; for(int i = 0; i < 1000000; i++) { do { val = count; } while (!atomic_compare_exchange_weak(&count, &val, val+1)); } pthread_exit(NULL); }-
用
perf测试代码:Performance counter stats for './test_free_lock' (10 runs): 804.76 msec task-clock:u # 1.768 CPUs utilized ( +- 3.99% ) 0 context-switches:u # 0.000 /sec 0 cpu-migrations:u # 0.000 /sec 83 page-faults:u # 93.230 /sec ( +- 0.24% ) <not supported> cycles:u <not supported> instructions:u <not supported> branches:u <not supported> branch-misses:u 0.4553 +- 0.0157 seconds time elapsed ( +- 3.45% )- 如上所示,运行10次脚本,平均耗时0.45秒。
-
-
spin-lock示例代码:#include <stdio.h> #include <stdatomic.h> #include <pthread.h> static void * adding(void *input); int count = 0; int lock = 0; int main() { pthread_t tid[10]; for(int i=0; i<10; i++) { pthread_create(&tid[i], NULL, adding, NULL); } for(int i=0; i<10; i++) { pthread_join(tid[i], NULL); } printf("the value of count is %d\n", count); } static void * adding(void *input) { int expected = 0; for(int i = 0; i < 1000000; i++) { // if the lock is 0(unlock), then set it to 1(lock) while(!atomic_compare_exchange_weak(&lock, &expected, 1)) { /* * if the CAS fails, the expected will be set to 1, * so we need to change it to 0 again. */ expected = 0; } count++; lock = 0; } }-
用
perf测试代码:Performance counter stats for './test_spin_lock' (10 runs): 7,277.08 msec task-clock:u # 1.993 CPUs utilized ( +- 4.31% ) 0 context-switches:u # 0.000 /sec 0 cpu-migrations:u # 0.000 /sec 75 page-faults:u # 10.415 /sec ( +- 0.31% ) <not supported> cycles:u <not supported> instructions:u <not supported> branches:u <not supported> branch-misses:u 3.652 +- 0.159 seconds time elapsed ( +- 4.37% )- 如上所示,运行10次脚本,平均耗时3.65秒。
-
-
对比两脚本的执行结果,
lock-free是明显优于spin-lock的。接着从程序代码的差异上分析,lock-free在一条语句上(atomic_compare_exchange_weak(&count, &val, val+1))完成了修改,而spin-lock则是“持有锁》修改值〉释放锁”。它们之间的差异可以由下两图体现:-
lock-free: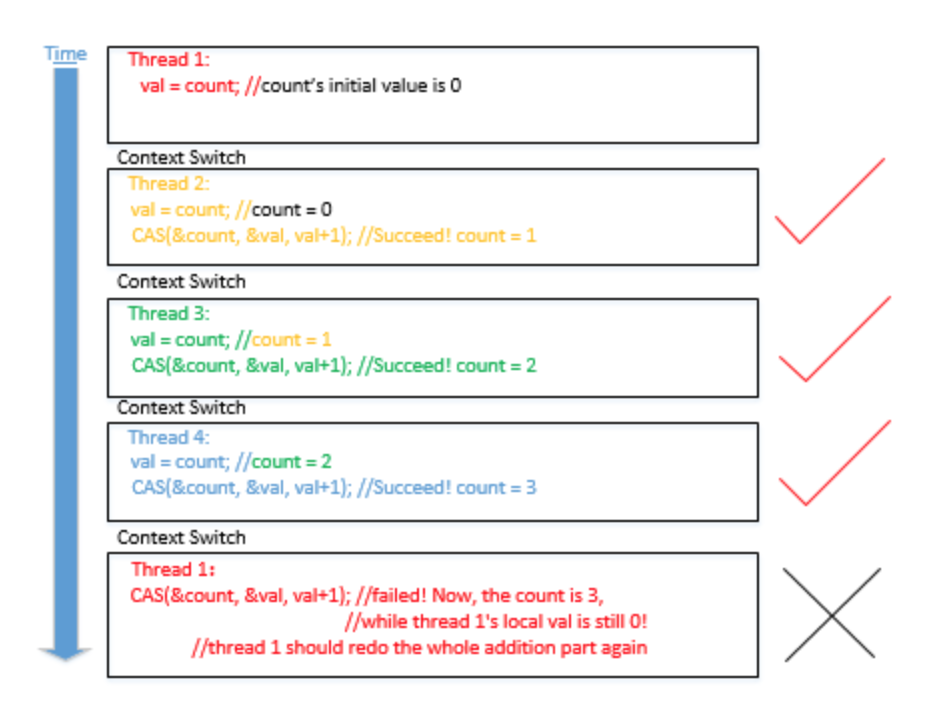
-
spin-lock: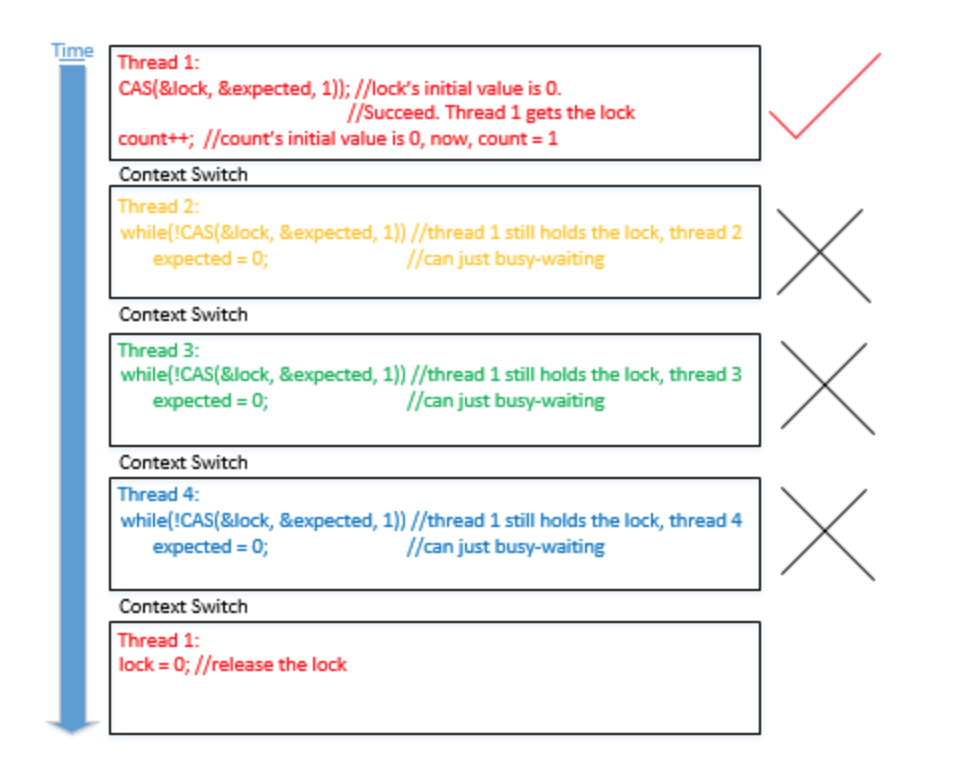
-
区别在于,使用
lock-free的线程可以分别独自的访问到共享变量count,而spin-lock在被其他线程持有锁之后,只能占着cpu空转。哪怕lock-free也会出现冲突,并且需要重新操作一次,但也仅限于此。因此在自身上下文中lock-free通常就能够完成操作,无需等待(出现冲突时只需要重新运行一次即可),而spin-lock则只能空转。
-
设计无锁队列(lock-free queue)¶
从上文中可以了解到lock-free是有一些局限性的,因为lock-free只能针对于某个特定的整数变量有效,而在实际场景中我们共享的数据一般都是复杂的,甚至是多个变量的。其次,我们也知道队列是一个FIFO模型,在入队和出队实质上就是一个操作队列的头(Header)和尾(Tail)的过程。也就是说在队列中会产生冲突的地方只有Header和Tail,那么只要对Header和Tail的操作可以满足CAS的操作即可将lock-free应用于此,但此时需要注意ABA的问题。
-
队列通用设计
tail index指示下一个生产者放置元素的位置。一直递增的值直到越界后回到起点。head index指示下一个可以被消费的元素的位置。一直递增- 为了防止
tail index达到或超过head index,增加了一个新的原子计数器dequeue counter,再实际操作dequeue之前,先增加它的值。如果在增加之后dequeue counter是小于tail index的,那么就可以保证可以dequeue到数据,同时也保证了增加head index的安全,因为随后增加head index也一定会小于tail index。当然,如果dequeue counter大于tail index,那么就等量的减少它的值,并使dequeue操作失败。 -
不过为了保证
dequeue counter也是保持单调递增的,因此引入一个新的原子计数器dequeue overcommit counter,增加它的值来替代去减少dequeue counter的值。因此实际的dequeue_n值的运算为:\[ \text{dequeue\_n} = \text{dequeue\_counter}\ -\ \text{dequeue\_overcommit\_counter} \] -
子队列逻辑上是环形的(实际上是一个数组),一个计算
a是否在b左侧(即 \(\overrightarrow{ab}\) 弧线小于 \(\overrightarrow{ba}\) )的算法如下:\[ a < b :\ a - b > (1U \ll 31U) $$ $$ a \le b :\ a - b - 1ULL > (1ULL \ll 31ULL) \]- 该算法可以让
a和b都用unsigned int类型值。队列中用它来确保tail index增长的过程中不会超过head index。
- 该算法可以让
-
无锁设计
- 通过未每个生产者创建一个相对应的子队列,来保证生产者之间的并发。
- 由于在空闲链表(
freeListHead)中存在ABA的问题(从空闲链表中获取Block时),而该问题的根本原因是freeListHead的头结点(head)被读取后,head.next的值已经被改变了,因此解决此ABA的根本方法就是去察觉到head.next的值是否发生改变。这里采用一个比较通用的方法:“对每个Block引入一个原子的计数器(Block.count),在读取Block.next之前加1,并在CAS之后减1,当Block.count不为0时不允许任何人改变Block.next的值(因为无法改变Block.next的值,因此Blcok就无法重新放回freeListHead,便杜绝了ABA的可能)”。- 这个
Block.count还有隐含的意思:“当一个Block使用完并要放回到freeListHead时,在实际放回到链表之前Block.count必须为0,否则啥也不做”。但如果是自旋的等待Block.count为0的话,那么其实就是一个自旋锁,考虑到最终是谁将Block添加到链表中并不重要,因此可以将“添加到freeListHead”的操作交给最后一个持有Block的线程。为此我们可以在Block上设置一个flag值告知最后一个持有Block的线程应该把它添加到freeListHead中(值用should_be_on_free_list表示)。利用这个flag值可以让add变成完全无锁。 - 但是flag和
Block.count之间仍然可能产生竞争,因此将Block.count的最高位作为flag使用,这样就能让他们变成原子的。
- 这个
-
性能设计:
- 生产者队列由一群
Block组成。每个Block可以存储一定数量的元素,能存储的元素个数是2的幂。另外Block中有一个标志标识队列是否为空(emptyFlags),还有一个变量指示完全dequeue的数量(elementsCompletelyDequeued)。 - 创建两个
Block pool:- 一个是预申请的
Block数组,一旦消费掉后,就一直保持空。该数组用一个简单的“fetch-and-add atomic”指令来完成消费(无需等待的),当然还需要检测一下是否在合理的范围之类。 -
另一个是全局的无锁的
Block空闲链表,那些被释放的Block会被放到该链表中等待重用。其实现就是一个无锁链表。- 初始时,
listHead = NULL -
添加一个
Block到链表中时:void add_knowing_refcount_is_zero(Block *freeListHead, Block *block) { /* * 到了这里意味着 block.count 一定是0, * 因此可以自由的更改 block.next 的值 */ while (1) { Block *head = freeListHead; block->next = head; /* * 这里把 block.count 值改为1后,将重新与 try_get() 产生竞争(ABA), * 因此 block.count 的值有可能在 try_get() 中被增加 */ block->count = 1; if (!CAS(freeListHead, head, block)) { /* * 添加失败后将引用计数减回去(上面设置成1), * 并通知最后一个持有该Block的线程去执行添加操作。 */ if (fetch_add(block->count, should_be_on_free_list - 1) == 1) { /* * 到这里意味着由我们自己执行 add 操作 */ continue; } } return; } } Block * add(Block *freeListHead, Block *block) { if (fetch_add(block->count, should_be_on_free_list) == 0) { add_knowing_refcount_is_zero(freeListHead, block); } } -
从链表中移除一个
Block时:Block * try_get(Block *freeListHead) { Block *head = freeListHead; while (head) { prevHead = head; count = head->count; /* * count为0时不能修改next,因此需要直接 continue。 * 如果 CAS 失败的话也需要 continue */ if ((count & REFS_MASK) == 0 || !CAS(head->count, count, count + 1)) { head = freeListHead; continue; } Block *next = head->next; if (CAS(freeListHead, head, next)) { /* 成功获取block后,需要将引用计数归0 */ fetch_add(head->count, -2); return head; } /* 获取失败需要将增加的引用计数重新减回去 */ count = fetch_add(head->count, -1); if (count == should_be_on_free_list + 1) { /* 由该线程负责执行 add 操作 */ add_knowing_refcount_is_zero(prevHead); } } return NULL; }
- 初始时,
- 一个是预申请的
- 生产者队列由一群
引用¶
-
cameron314/concurrentqueue:一个
C++项目。支持MPMC模型的无锁队列- a-fast-general-purpose-lock-free-queue-for-c++:设计无锁队列的一般目标
- detailed design of a lock free queue:无锁队列的详细设计
- aba problem:讲解作者解决ABA问题的思路
-
Lock-free vs spin-lock:一篇讲解无锁跟自选锁区别的文章